MongoDB高手课笔记
前言
这是极客时间的《MongoDB高手课》视频课程做的笔记。中间件会持续更新。视频课程可以自己搜一下,极客时间的山寨课很多,就是声画不同步看着有点不舒服而已,正版也不贵,新人首单是59。课程介绍说看完这个可以说自己精通MongoDB,欢迎大家在评论区反馈。
MongoDB再入门
关于MongoDB
| Question | Answer |
|---|---|
| 什么是 MongoDB? | 一个以 JSON 为数据模型的 文档数据库 |
| 为什么叫 文档数据库? | 文档来自于 JSON Document,并非我们一般理解的 PDF,WORD文档 |
| 谁开发的 MongoDB? | 上市公司 MongoDB Inc. ,总部位于美国纽约 |
| 主要用途 | 1. 应用数据库,类似于Oracle,MySQL 2. 海量数据处理,数据平台 |
| 主要特点 | 1. 建模为可选 2. JSON数据模型比较适合开发者 3. 支持横向扩展,支持大数据量和并发 4. 从4.0版本开始支持ACID事务 |
MongoDB VS 关系型数据库
| MongoDB | RDBMS | |
|---|---|---|
| 数据模型 | 文档类型 | 关系模型 |
| 数据库类型 | OLTP(Online Transaction Processing,联机事务处理) | OLTP(Online Transaction Processing,联机事务处理) |
| CRUD操作 | MQL/SQL | SQL |
| 高可用 | 复制集 | 集群模式 |
| 横向扩展能力 | 通过原生分片完善支持 | 数据分区、应用侵入式(如分库分表) |
| 索引支持 | B树,全文索引,地理位置索引,多键索引,TTL索引 | B树,B+树 |
| 开发难度 | 容易 | 困难 |
| 数据容量 | 没有理论上限 | 千万、亿 |
| 扩展方式 | 垂直扩展+水平扩展 | 垂直扩展 |
MongoDB的特色以及优势
-
简单直观:以自然的方式来建模,以直观的方式来交互。如订单模块,需要用几张表来表示
订单-订单明细,MongoDB可以直接用一个集合来表示这个对象。通俗的讲复杂对象只需要用一个表(集合) -
结构灵活:弹性模式,从容响应需求的频繁变化
-
多形性:同一个集合可以包含不同字段(类型)的文档对象
-
动态性:线上修改数据模式,修改时应用和数据库无需下线重启
-
数据治理:支持使用JSON schema

-
-
快速开发:做更多的事,写更少的代码
- 数据库引擎只需要在一个存储区读写。数据库查询操作耗时最长的步骤在定位上,如果有这个一个对象,关系型数据需要6个表,至少需要定位6次,但是在MongoDB只需要一个查询语句定位一次。
- 反范式,无关联的组织极大的优化查询速度
- 程序API自然,快速开发
-
原生的高可用和横向扩展能力:多中心容灾,自动故障转移
MongoDB基本操作
使用 insert 完成插入操作
操作格式:
db.<集合>.insertOne(<JSON对象>)db.<集合>.insertMany([<JSON 1>, <JSON 2>, ..., <JSON n>])
示例:
1 | db.fruit.insertOne({name:"apple"}) |
使用 find 查询文档
关于find:
find是 MongoDB 中查询数据的基本指令,相当于SQL中的 Selectfind返回的是游标
find示例:
1 | db.movies.find({"year":1975}) //单条件查询 |
SQL 和 MQL对照表
| SQL | MQL |
|---|---|
| a=1 | { a: 1} |
| a<>1 | { a: { $ne: 1}} |
| a>1 | { a: { $gt: 1}} |
| a>=1 | { a: { $gte: 1}} |
| a<1 | { a: { $lt: 1}} |
| a<=1 | { a: { $lte: 1}} |
| a=1 AND b=1 | {a: 1,b: 1} 或 {$and:[{a: 1}, {b: 1}]} |
| a=1 OR b=1 | {$or:[{a: 1}, {b: 1}]} |
| a IS NULL | {a:{$exist: false}} |
| a IN (1,2,3) | {a: {$in: [1, 2, 3]}} |
| a NOT IN(1,2,4) | {a: {$nin: [1, 2, 3]}} |
查询逻辑运算符
$lt:存在并小于$lte:存在并小于等于$gt:存在并大于$gte:存在并大于等于$ne:不存在或存在但不等于$in:存在并在指定数组中$nin:不存在或不在指定数组中$or:匹配两个或多个条件中的一个$and:匹配全部条件
使用 find 查询
find 支持 field.sub_field的形式查询子文档。假设有一个文档:
1 | db.fruit.insertOne({ |
查询语句
1 | db.fruit.find({"from.country":"China"}) |
使用find搜索数组中的对象
考虑以下文档,在其中搜索
1 | db.movies.insertOne({ |
指定返回字段
- find可以指定只返回某些字段
- _id字段必须明确指明不返回,默认返回
- 在
MongoDB中我们称之为 投影(projection) db.movies.find({"category":"action"},{_id:0,title:1})中,第二个对象为 投影字段,为0表示不返回
使用 remove 删除文档
-
remove需要配合查询条件来使用 -
匹配到的文档会被删除
-
指定一个空文档查询条件会删除所有数据
-
以下为示例
1
2
3
4db.testcol.remove({a:1}) // 删除a = 1的数据
db.testcol.remove({a: {$lt:1}}) // 删除a < 1的数据
db.testcol.remove({}) // 删除所有数据
db.testcol.remove() // 报错
使用 update 更新文档
-
update操作格式:db.<集合>.update(<查询条件>,<更新字段>) -
以下数据为例
1
2db.fruit.insertMany([{name:"apple"},{name:"pear"},{name:"orange"}])
db.fruit.updateOne({name:"apple"},{$set: {from: "China"}}) //$set指令可以修改原字段,也可以新增字段 -
updateOne只会更新匹配到的第一条数据 -
updateMany表示匹配到多少条就更新多少条 -
updateOne/updateMany方法要求更新部分必须具备一下条件之一,否则报错:-
$set/$unset: -
$push/$pushAll/$pop:增加一个对象到数组底部 / 增加多个对象到数组底部 / 从数组底部删除一个对象 -
$pull/$pullAll:如果匹配到相应的值则从数组中删除相应的对象 / 如果匹配到任意的值,从数组中删除相应的对象 -
$addToSet:如果不存在则新增一个值到数组 -
$inc:预聚合,适合排行榜,点击率等场景。(在chatgpt中提问,说MongoDB中的预聚合是线程安全的,可以自行查证)1
2
3
4
5
6
7
8
9
10
11db.inventory.update(
{_id:123},
{
$inc:{
quantity: -1,
daily_sales: 1,
weekly_sales: 1,
monthly_sales: 1
}
}
)
-
使用 Drop 删除一个集合
- 使用
db.<集合>.drop()删除一个集合 - 集合中所有文档会被删除
- 集合相关的索引也会被删除
MongoDB的聚合查询
聚合运算的基本格式
1 | pipeline = [$stage1, $stage2, ..., $stage3] |
常见步骤
| 步骤 | 作用 | SQL等价运算符 |
|---|---|---|
| $match | 过滤 | WHERE |
| $project | 投影 | AS |
| $sort | 排序 | ORDER BY |
| $group | 分组 | GROUP BY |
| $skip 和 $limit | 结果集限制 | SKIP/LIMIT |
| $lookup | 左外连接 | LEFT OUTER JOIN |
| $unwind | 展开数组 | – |
| $graphLookup | 图搜索 | – |
| $facet 和 $bucket | 分面搜索 | – |
常见步骤中的运算符
| $match | $project | $group |
|---|---|---|
| $eq / $gt / $gte / $lt / $lte $and / $or / $not / $in $geoWithin / $intersect … … |
选择需要的或不需要的字段 $map / $reduce / $filter $range $multiply / $divide / $substract / $add $year / $month / $dayOfMonth / $hour / $minute / $second … … |
$sum / $avg $push / $addToSet $first / $last / $max / $min … … |
聚合查询示例:
分页查询男性用户名字
1 | SELECT FIRST_NAME AS '名', LAST_NAME AS '姓' FROM Users WHERE GENDER = '男' SKIP 100 LIMIT 20 |
1 | db.users.aggregate([ |
每个部门女员工的数量
1 | SELECT DEPARTMENT, COUNT(*) AS EMP_QTY |
1 | db.users.aggregate([ |
数组展开 unwind
1 | //元数据 |
MQL特有步骤Bucket
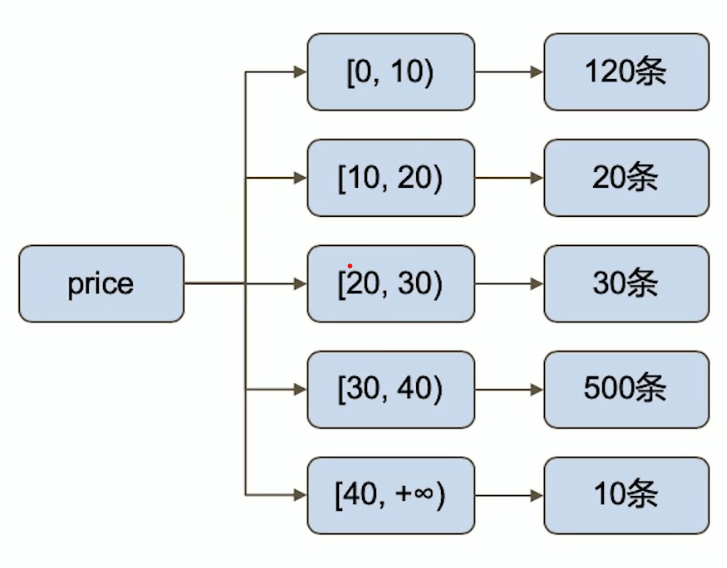
1 | db.products.aggregate([ |
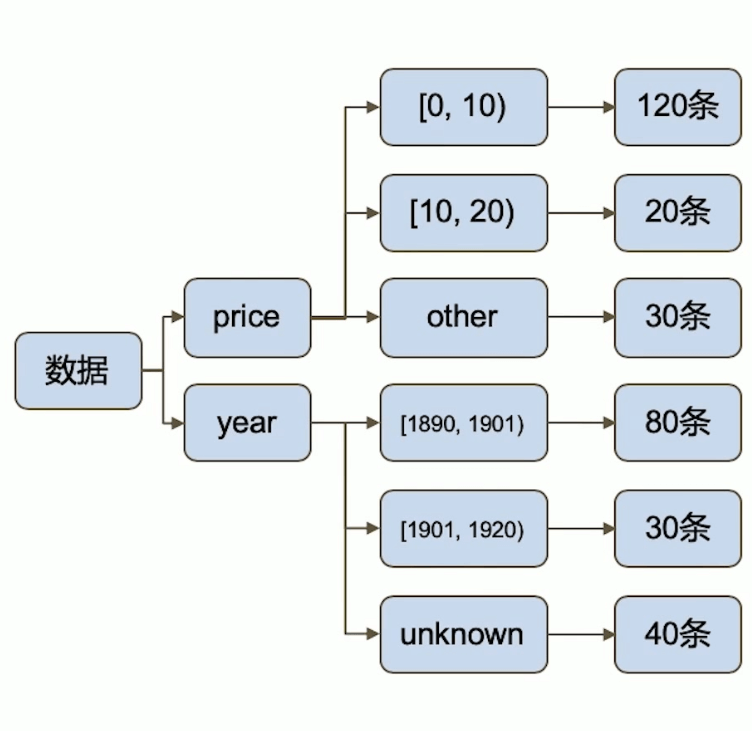
1 | //组合bucket用facet |
复制集机制与原理
复制集的作用
- 主要意义在于实现高可用
- 它的现实依赖与两个方面的功能
- 数据写入时快速复制到另一个节点上
- 接受写入数据的节点发生故障时,自动选举出另一个节点替代。(故障自动转移)
- 实现高可用的同时,复制集的其他几个作用
- 数据分发:将数据从一个区域分发到另一个区域,减少另一个区域的读延迟
- 读写分离:不同类型的压力分到不同的节点上
- 异地容灾:在数据中心发生故障时,快速切换到异地
典型的复制集结构
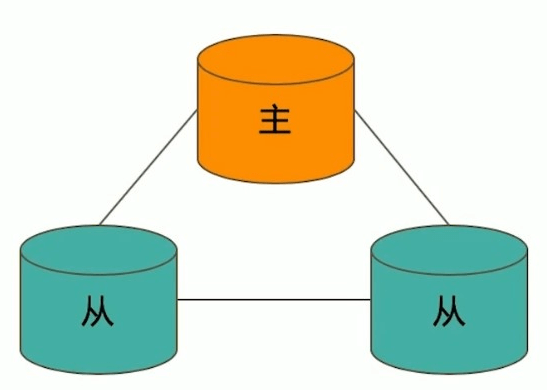
一个典型的复制集结构至少由三个具有投票权的节点组成,包括:
- 一个主节点(Primary):接受写入操作和选举时投票
- 两个以上从节点(Secondary):复制主节点的数据和选举时投票
- 不推荐使用Arbiter节点(投票节点,类似于Redis的Sentinel)
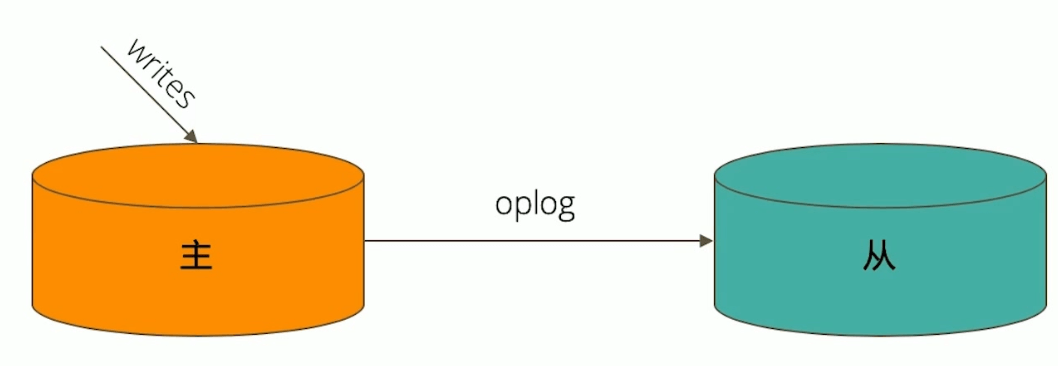
数据是如何复制的?
- 当一个写操作到达主节点时,它会被记录下来,这些称之为
oplog - 从节点 通过在 主节点 打开一个 tailable 游标不断获取新进入主节点的
oplog,并在自己的数据上回放,来保持和主节点的数据一致
通过选举完成故障恢复
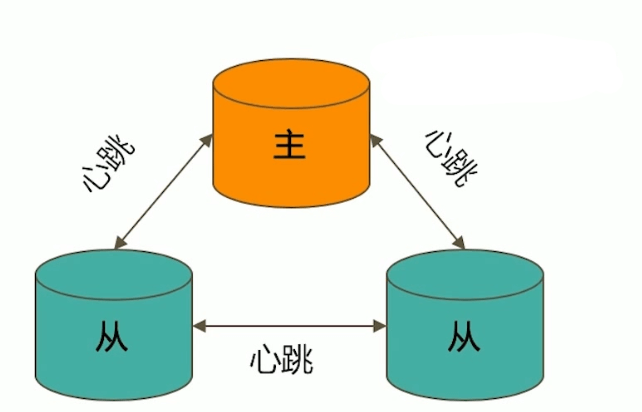
- 具有投票权的节点相互发送心跳,5次心跳失联认为节点故障。
- 如果失联的是主节点,从节点会进行选举,选出新的主节点;如果是从节点,则不影响。
- 选举基于
RAFT一致性算法实现,选举成功的条件是大多数投票节点存活。 - 复制集最多可以有50个节点,但具有投票权的最多有7个。
影响节点选举的因素
- 整个集群必须有大多数节点存活着
- 被选为主节点的节点必须:
- 能够与多数的节点建立连接
- 拥有最新的oplog
- 具有较高的优先级(如果有配置的话)
增加从节点不会提高系统写入的性能
从熟练到精通的开发之路
MongoDB 文档模型设计的三个误区
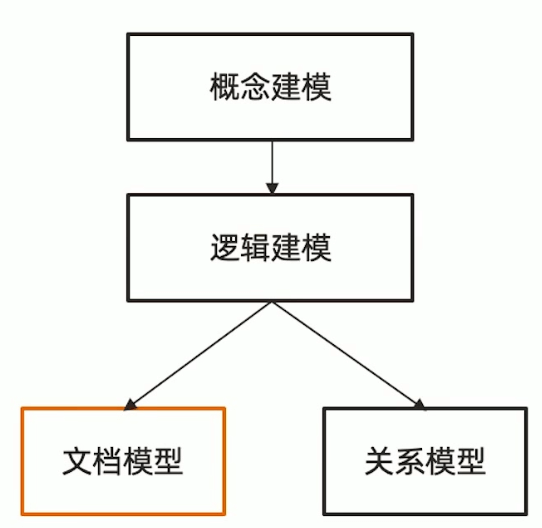
-
不需要模型设计 错误
MongoDB同样需要概念/逻辑建模,只是和关系型数据库的建模不一样,没有主外键的部分。并且,文档模型设计的物理结构可以和逻辑层类似。所以物理模型这个步骤可以被省略
-
MongoDB 用一个超大的文档来组织所有的数据 错误,不可能也不现实
-
MongoDB 不支持事务 错误,4.0开始支持ACID事务
| 关系型数据库 | MongoDB | |
|---|---|---|
| 模型设计层次 | 概念模型 逻辑建模 物理模型 |
概念模型 逻辑建模 |
| 模型实体 | 表 | 集合 |
| 模型属性 | 列 | 字段 |
| 模型关系 | 关联关系,主外键 | 内嵌数组,引用字段 |
文档模型设计
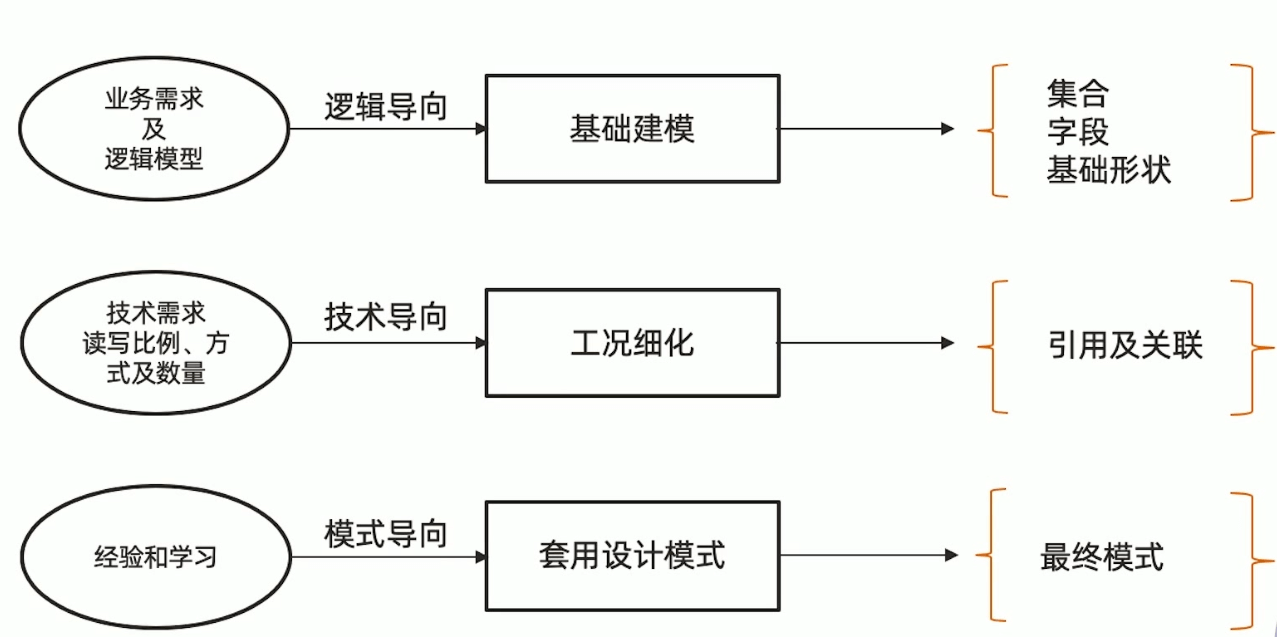
第一步:建立基础文档模型
- 根据概念模型或者业务需求推导出逻辑模型 - 找到对象
- 列出实体之间的关系 (及基数) - 明确关系(一对多,一对一,多对多)
- 套用逻辑设计原则来决定内嵌方式 - 进行建模
- 完成基础模型构建
第二步:根据读写工况细化
-
最频繁的数据查询模式
-
最常用的查询参数
-
最频繁的数据写入模式
-
读写操作比例
-
数据量大小
-
基于内嵌文档的模型,根据业务需求:
- 使用引用来避免性能瓶颈
- 使用冗余来优化访问性能
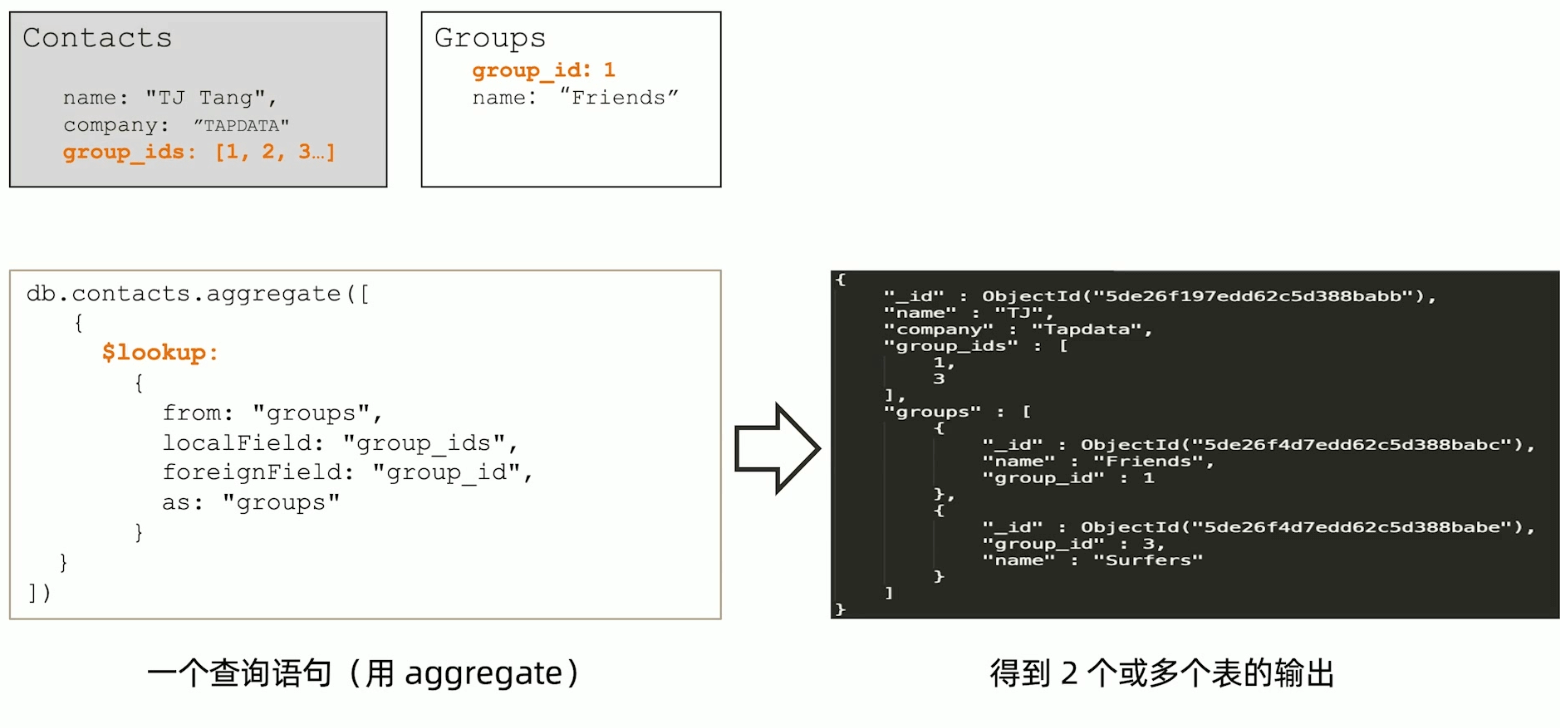
这个有点想mybatis里关联查询 association ,这种在mysql中容易造成 N+1的问题,但是在 MongoDB 中,是相当于 LEFT OUTER JOIN。
MongoDB引用设计模式的一些限制
- MongoDB在使用引用的集合中并无主外键检查
- MongoDB使用聚合查询的
$lookup来模仿关联查询 $lookup只支持Left Outer Join$lookup的关联目标(from)不能是分片表
第三步:套用设计模式
-
文档模型:无范式,无思维定式,充分发挥想象力
-
设计模式:实战过屡试不爽的设计技巧,快速应用
-
举例:一个IoT场景的分桶设计模式,可以帮助把存储空间降低10倍,并且提高查询效率数十倍
1 | //每分钟一个文档 |
事务
什么是 writeConcern?
writeConcern 决定一个写操作落到多少个节点才算成功。writeConcern取值包括:
- 0:发起写操作,不关心是否成功
- 1~集群最大数据节点数:写操作需要被复制到指定节点数才算成功。
- majority:写操作落到大多数节点中才算成功
发起写操作的程序将阻塞到写操作到达指定节点数为止。默认为主节点成功就成功。
writeConcern 实验
-
在复制集测试writeConcern参数
1
2
3db.test.insert( {count: 1}, { writeConcern: {w: "majority" }})
db.test.insert( {count: 1}, { writeConcern: {w: 3 }})
db.test.insert( {count: 1}, { writeConcern: {w: 4 }}) -
配置延迟节点,模拟网络延迟(复制延迟)
1
2
3
4conf=rs.conf()
conf.members[2].slaveDelay = 5
conf.members[2].priority = 0 //配置成不可以参与选举的节点
rs.reconfig(conf) -
观察复制延迟下的写入,以及timeout参数
1
2db.test.insert( {count: 1}, { writeConcern:{w: 3}})
db.test.insert( {count: 1},{ writeConcern: {w: 3, wtimeout:3000 }}) // 这里同步延迟时间为5s,但是等待3s会报错,数据实际上已经写进去了,实际业务场景中,最好做一个日志,方便回查
读操作事务
读数据操作中需要关注两个问题
- 从哪里读?关注节点位置 (readReference)
- 什么样的数据可以读?关注数据的隔离性 (readConcern)
什么是readReference?
readReference决定使用哪一个节点来满足正在发起的读请求,可选值包括:
- primary:只选择主节点;
- primaryPreferred:有限选择主节点,如果不可用则选择从节点
- secondary:只选择从节点
- secondaryPreferred:有限选择从节点,如果从节点不可用则选择主节点
- nearest:选择最近的节点
场景举例:
- 用户下订单后马上将用户转到订单详情页——primary/primaryPreferred。因为此时从节点可能还没复制到新订单
- 用户查询自己下过的订单——secondary/secondaryPreferred。查询历史订单时效性通常没有太高要求
- 生成报表——secondary。报表对时效性要求不高,但资源需求大,可以在从节点单独处理,避免对线上用户造成影响
- 将用户上传的图片分发到全世界,让各地用户能就近读取——nearest。每个地区的应用选择最近的节点读取数据
readReference 与 tag
readReference只能控制使用一类节点,Tag可以更精准控制请求打到某几个节点。
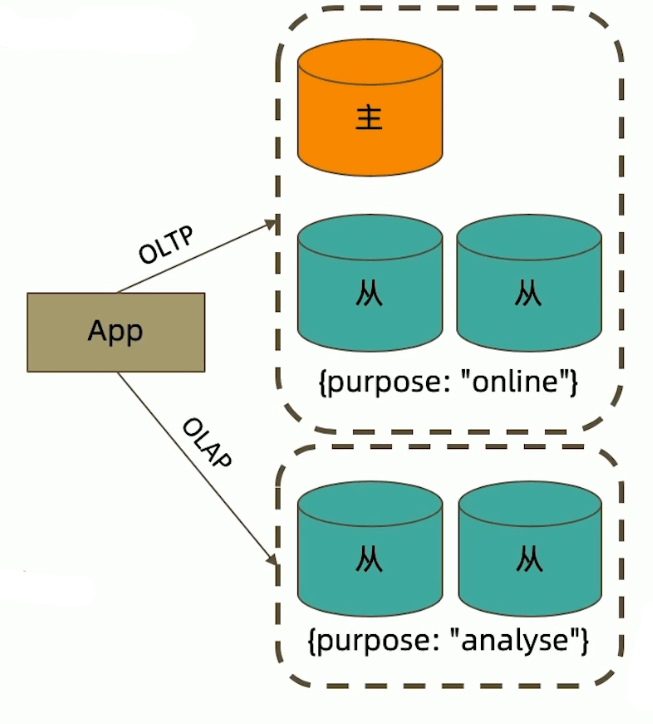
readReference 配置
- 通过MongoDB的连接串参数:
mongodb://host1:27107,host2:27107,host3:27017/?replicaSet=rs&readPreference=secondary - 通过MongoDB驱动程序API:
MongoCollection.withReadPreference(ReadReference eadRef) - MongoShell:
db.collection.find({}).readPref("sencondary")
可以使用 db.fsyncLock()来锁定写入,解除从节点锁定使用 db.fsyncUnlock()
配置了readReference/tag时,如果对应的节点失效则读操作失败,如主节点,则发生故障转移期间没有节点可读。
什么是readConcern
readPreference选择了指定节点后,readConcern决定这个节点上的数据那些是可读的,类似于关系数据库的隔离级别。可选值包括:
- available:读取所有可用数据
- local:读取所有可用且属于当前分片的数据
- majority:读取在大多数节点上提交完成的数据(mvcc实现,相当于RC)
- linearizable:可线性化读取文档
- snapshot:读取最近快照中的数据(相当于RR)
ACID多文档事务支持
| 事务属性 | 支持程度 |
|---|---|
| Atomicity 原子性 | 4.2开始支持分片集群多表多文档 |
| Consistency 一致性 | writeConcern,readConcern |
| Isolation 隔离性 | readConcern |
| Durability 持久性 | Journal and Replication |
使用示例(java)

其实也可以使用@transactional,配置好事务管理器就行
分片集群与高级运维之道
MongoDB常见的部署架构
MongoDB的分片类似于Mysql的分库分表。但是MongoDB天生支持分片。分片数最多可以达到1024。
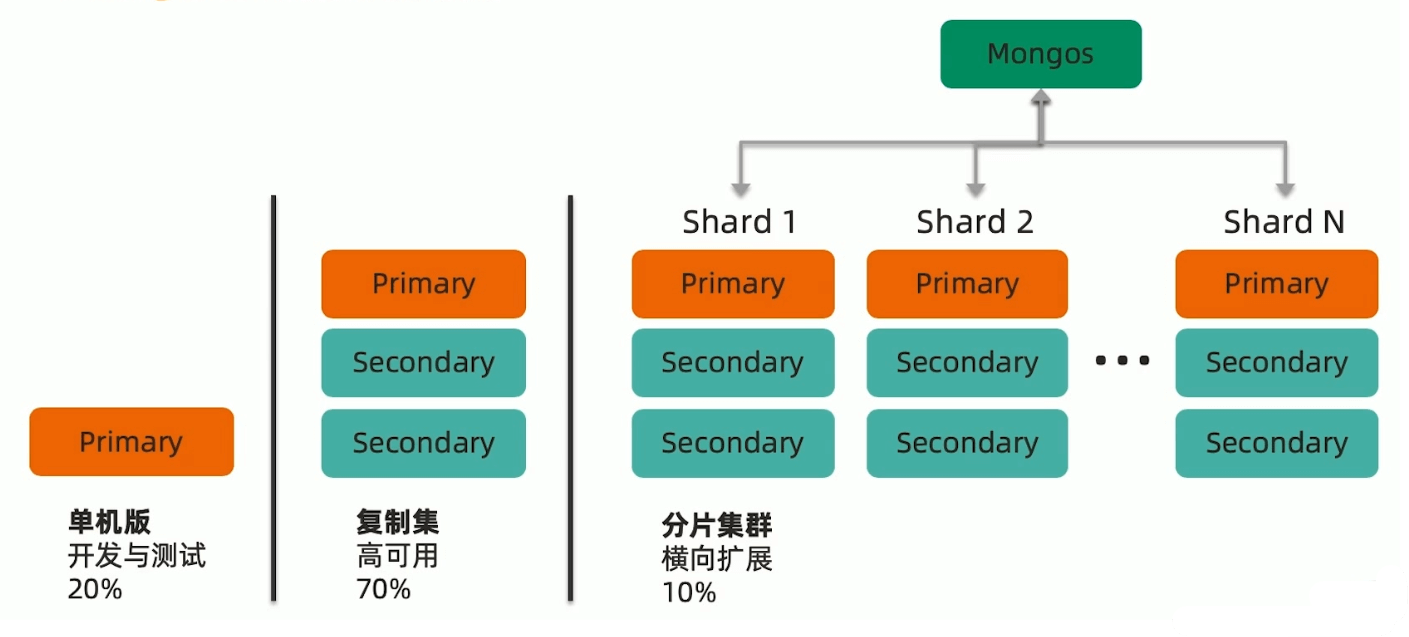
为什么要使用分片集群
可能的场景
- 数据容量日益增大,访问性能日渐降低
- 新品上线异常火爆,如何支持更多的并发用户
- 单库已有10TB数据,恢复需要1-2天
- 地理分布数据
- ……
分片集群构成
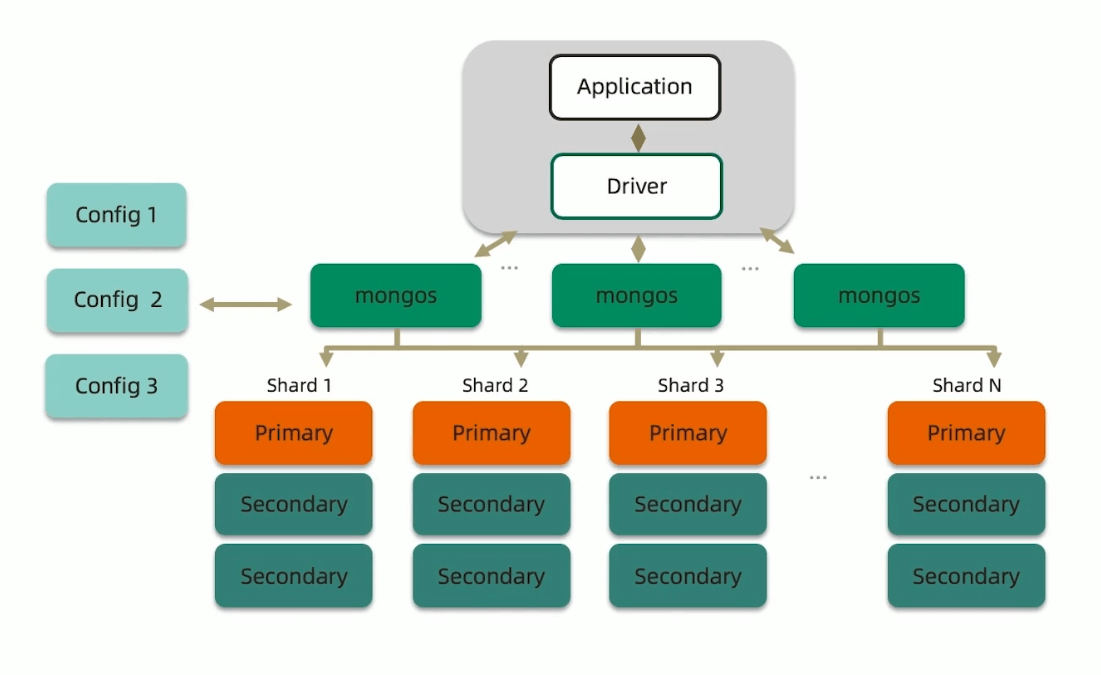
- 路由节点 mongos:为集群提供单一的入口,转发应用端的请求,选择合适的数据节点进行读写,合并多个数据节点的返回。无状态,建议至少两个(高可用和负载均衡)。
- 配置节点 Config:提供集群元数据存储,分片数据分布的映射。普通的复制集架构。
- 数据节点 Shard:以复制集为单位,横向扩展,最多1024片,分片之间数据不重复,必须所有的分片缺一不可。
MongoDB分片集群的特点
- 应用全透明,无特殊处理:单复制集的架构可以无缝升级成分片集群,应用无需特殊处理
- 数据自动均衡:分片之间的数据自动平衡,如果检测到分片的数据不平衡,会自动均衡
- 动态扩容,无须下线
- 提供三种分片方式
- 基于范围
- 基于hash
- 基于zone / tag
MongoDB分片方式
基于范围
基于数值范围对数据进行逻辑分块(chunk),而不是物理分块。
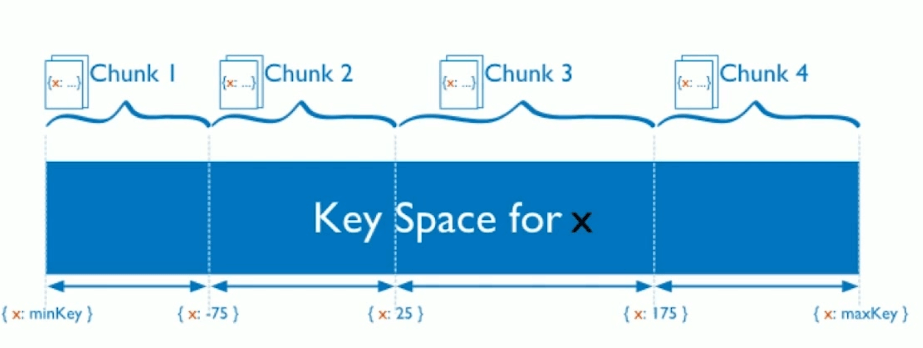
优点:片键范围查询性能好,优化读
缺点:数据极易出现分布不均,容易有热点。如自增主键有可能导致数据一直在某个分块写数据。
基于Hash
和基于范围分片方式优劣相反,根据片键的hash值分布到不同的chunk中。
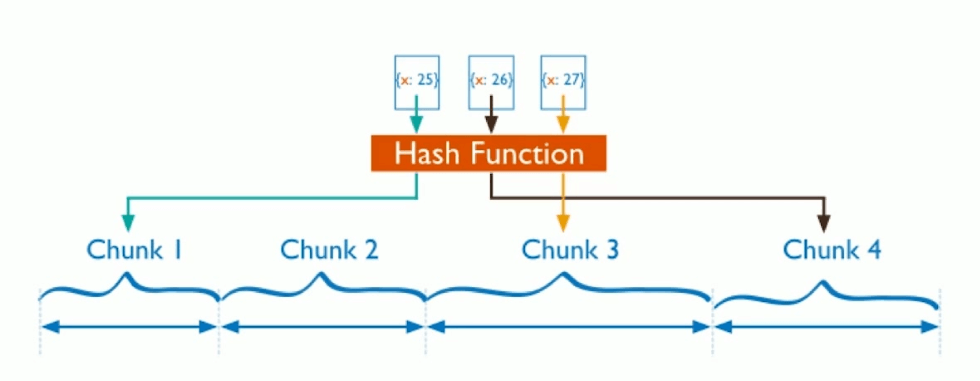
优点:分布均匀,写优化,适合写操作非常多的情况,如日志、物联网等高并发的场景
缺点:范围查询效率低,因为数据不连续。
基于 Zone / Tag
根据特定的标签进行分片,如不同的地域读写操作在最近的机房节点中。
分片集群的设计

合理的架构
分片的大小
- 关于数据:数据量不超过3TB,尽可能保持在2TB一个片;
- 关于索引:常用索引必须纳入内存。
分片数量:经验公式
- A = 所需存储总量 / 单服务可挂载容量
- B = 工作集大小 / (单服务内存容量 * 0.6)
- C = 并发总数 / (单机并发总数 * 0.7)
- 分片数 = MAX(A, B, C)
分片的其他需求
- 是否需要跨机房分布分片?
- 是否需要容灾?
- 高可用的要求如何?
正确的姿势
各种术语
各种概念有效到大
- 片键 shard key:文档中的一个字段;
- 文档 doc:包含 shard key 的一行数据;
- 块 Chunk:包含 n 个文档;默认大小为64MB,系统自动规划,无需配置。
- 分片 Shard:包含 n 个 chunk;
- 集群 Cluster: 包含 n 个分片。
选择基数大的片键
类似于Mysql的索引条件,离散程度选择大的。
对于小基数的片键:
- 因为备选址有限,那么快的总数量就有限;如性别,只能有两块
- 随着数据增多,块的大小会越来越大
- 太大的块会导致水平扩展移动块会非常困难
对于分布不均匀的片键:
- 造成某些块的数据量急剧增大
- 这些快压力随之增大
- 数据均衡以chunk为单位,所以系统无能为力
定向性好
对主要查询要具有定向能力。例如,4个分片的集群,你希望读某条特定的数据。如果你用片键作为条件查询,mongos可以直接定位到具体的分片。反之,mongos 需要把查询发到4个分片,等到所有的分片都响应,mongos 才能响应应用端
足够的资源
- mongos 与 config 通常消耗较少的资源,可以使用低规格的服务器。mongos可以配置多一点的CPU,因为它需要创建很多的连接。
- shard 需要更多的资源
- 需要足以容纳热点数据索引的内存
- 正确创建索引后,CPU通常不会成为瓶颈,除非设计非常多的运算
- 磁盘尽量选择SSD
- 在各项指标达到60%就要开始考虑扩容升级
性能诊断工具
常用的监控工具和手段
- MongoDB Ops Manager(企业版,收费)
- Percona
- 通用监控平台,如grafana
- 程序脚本
如何获取监控数据
- 监控信息来源:
db.serverStatus()db.isMaster()mongoStats命令行工具(只有部分信息)
- 注意:
db.serverStatus()包含的监控信息是从上次看机到现为止的累计数据,不能简单使用
serverStatus()主要信息
- connections:关于连接数的信息
- locks:关于MongoDB使用的锁情况
- network:CRUD的执行次数统计
- opcounters:CRUD的执行次数统计
- repl:复制集的配置信息
- wiredTiger:包含大量WiredTiger执行情况的信息
- block-manager:WT数据块的读写情况
- session:session使用数量
- concurrentTransactions:Ticket使用情况
- mem:内存使用情况
监控报警的考量
-
具备一定的容错机制一减少误报的发生
-
总结应用各指标峰值
-
适时调整报警阈值
-
留出足够处理时间
-
建议监控指标
指标 意义 获取 opcounters 查询、更新、插入、删除、getmore 和其他命令的数量 db.serverStatus().opcounterstickets(令牌) 对 WiredTiger 存储引擎的读/写令牌数量。令牌数量表示可以进入存储引擎的并发操作数 db.serverStatus().wiredTiger.concurrentTransactionreplication lag(复制延迟) 写操作到达从节点所需的最小时间。 db.adminCommand({ "replSetGetStatus": 1 })oplog window(复制时间窗) oplog所能容纳多长时间的写操作。即从节点允许宕机的最大时间,否则从节点数据会出现部分丢失。建议在24小时以上 db.oplog.rs.find().sort({ $natural: -1 }).limit(1).next().ts-db.oplog.rs.find().sort({ $natural: 1 }).limit(1).next().tsconnections(连接数) 连接数应作为监控指标的一部分,因为每个连接都将消耗资源。应该计算低峰/正常/高峰时间的连接数,并制定合理的报警阈值范围 db.serverStatus().connectionsQuery Targeting(查询专注度) 索引键/文档扫描数量比返回的文档数量,按秒平均。如果该值比较高表示查询系需要进行很多低效的扫描来满足查询。这个情况通常代表了索引不当或缺少索引来支持查询 var status = db.serverStatus()status.metrics.queryExecutor.scanned / status.metrics.document.returnedstatus.metrics.queryExecutor.scannedObjects / status.metrics.document.returnedScan and Order (扫描和排序) 每秒内内存排序操作所占的平均比例。内存排序的成本可能会十分昂贵,因为它们通常要求缓冲大量数据。如果有适当索引的情况下,内存排序是可以避免的 var status db.serverStatus()status.metrics.operation.scanAndOrderstatus.opcounters.query节点状态 每个节点的状态,如果状态节点不是 PRIMARY、SECONDARY、ARBITER中的一个,或无法执行上述的命令则报警db.runCommand('isMaster')dataSize(数据大小) 整个实例数据总量(压缩前) 每个DB执行 db.statsStorageSize(磁盘空间) 已使用的磁盘空间占总空间的百分比
MongoDB的备份和恢复
备份的目的
- 防止硬件故障引起的数据丢失
- 防止人为误删数据
- 时间回溯
- 监管要求
MongoDB的备份机制
有点类似与redis的RDB和AOF,可以对比加深理解
- 延迟节点备份
- 全量备份 + Oplog增量
- mongodump
- 复制数据文件
- 文件系统快照
MongoDB安全架构
略。和开发关系不大。
MongoDB索引
术语
- index索引、key键、DataPage数据页
- Covered Query - 索引覆盖查询,对比Mysql
- IXSCAN 索引扫描 、COLLSCAN 集合扫描(全表扫描)
- Query Shape 查询形状,即查询用到了哪些字段
- Index Prefix 索引前缀,参考Mysql最左匹配原则
- Selectivity 过滤性,参考Mysql的数据离散度说法
B-树
索引执行计划
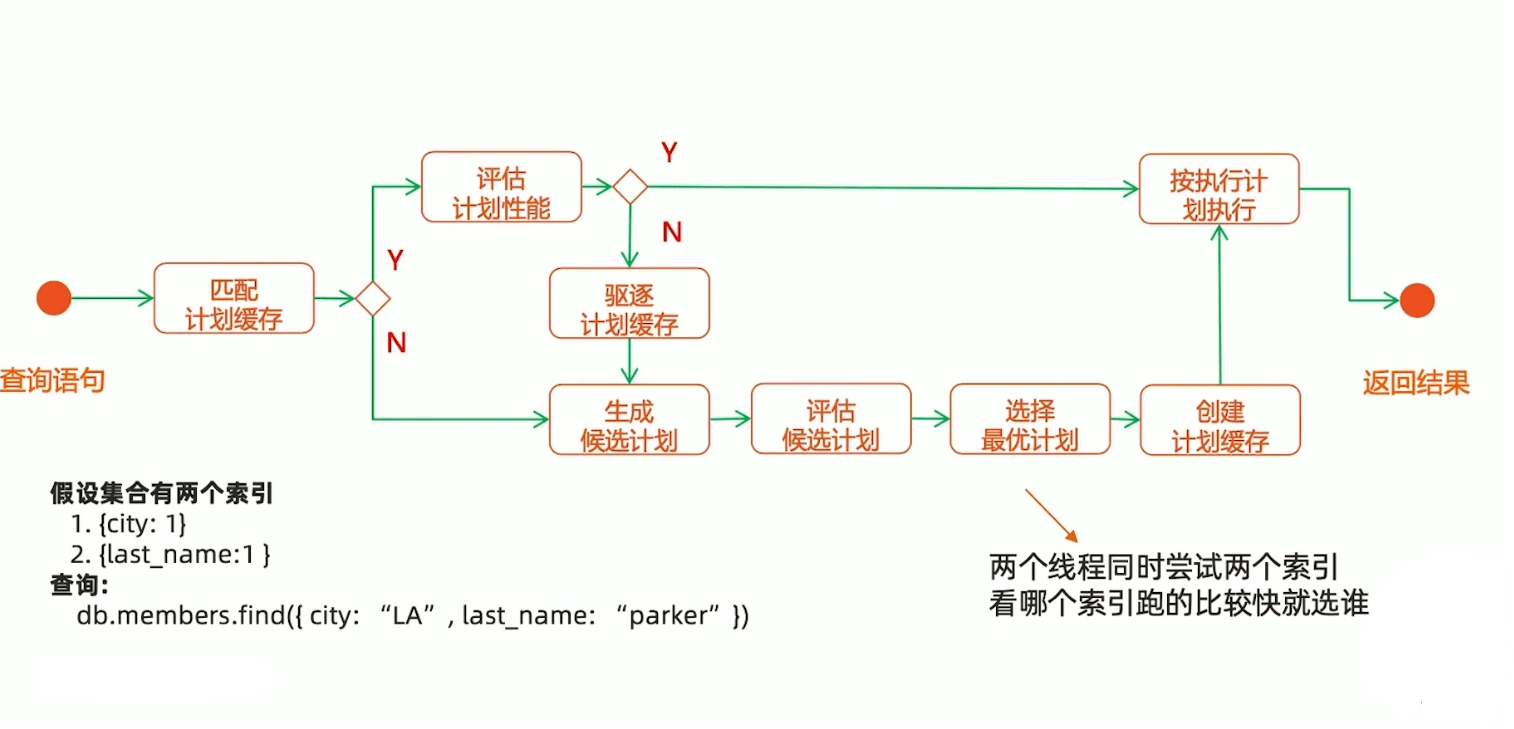
假设有两个索引
1 | db.createIndex({ "city": 1 }) |
那么查询语句
1 | db.find({"city": "LA","last_name": "Parker"}) |
问题:会走哪个索引?
和Mysql类似,会先尝试走哪个索引比较快,最终还是成本的问题。具体流程是先两个索引都各查1000条,看哪个返回快,然后走哪个,然后把这个查询计划保存起来,下次继续使用。但是MongoDB选择的有时候并非是最优索引,这时候可以通过配置实现
1 | db.collection.find({ "field": "value" }).hint({ "indexName": 1 }) |
MongoDB索引类型
-
单键索引:单一字段
-
组合索引:多个字段。遵循
ESR原则ESR原则:
- 精确 - Equals:匹配的字段放最前面,E有很多的时候,考虑E的离散度,离散程度越高的排越前面
- 排序 - Sort:条件放中间
- 范围 - Range:范围放最后
- 同样适用于ES/ER
例如:
有
db.members.find({gender: F, age:{$gte: 18}}).sort({"join_date": 1})遵循ESR原则就是
db.members.createIndex({"gender": 1,"join_date": 1, "age": 1 }) -
多值索引:从属字段,如
field.sub_field -
地理位置索引:地理位置索引,用的不多,但是很实用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//创建索引
db.geo_col.createIndex(
{location: "2d"},
{min: -20, max: 20, bits: 10},
{collation: { locale: "simple" }}
)
//查询
db.geo_col.find({
location:{
$geoWithin:{
$box:[ //查询在这个正方形中的数据
[1,1],
[3,3]
]
}
}
}) -
全文索引:只能说专业的事情给专业的中间件做吧,课程讲了这个是新功能,不太成熟,在数据量小,准确度要求不高的情况下可以用。还不如直接上elasticsearch
-
TTL索引:设置数据过期时间,类似于redis的功能
1
2
3
4//在date_created的十秒后失效
db.collection.createIndex({date_created: new Date('2019-01-03T16:00:00Z')},{expiredAfterSeconds: 10000})
//在特定时间失效可以把expiredAfterSeconds设置为0,把时间索引字段设置为过期时间
db.collection.createIndex({expiredAt:new Date('2022-01-03T16:00:00Z')},{expiredAfterSeconds: 0}) -
部分索引:针对部分数据建索引,这个是Mysql不具备的。
1
2//针对a大于等于5的数据建索引
db.collection.createIndex({a: 1},{partialFilterExpression: {a: {$gte: 5}}}) -
哈希索引
后续部分和开发关系不大,不看了,感兴趣的可以自己去看下
企业架构师进阶之法
主要是讲一些案例,建议看视频好一点。MongoDB高手课


